Custom Dynamics
The simulation calculates mass/inertia terms, simplified Coriolis terms, reaction torques, Euler integration, base motion, and joint angular velocities.
Zero-g robotics / Unity ML-Agents / imitation learning
A simulated servicing robot learns to rendezvous with a moving target satellite, enter station, and lightly touch a target point with a robotic end effector in zero gravity.
What this proves
The project models a servicing vehicle, three-joint robotic arm, and moving target object in a 2D zero-gravity simulation. Unity ML-Agents trains a policy using PPO, behavioral cloning, and GAIL to coordinate station-keeping, joint torques, and soft end-effector contact.
Demo video
The demo shows the trained policy moving toward the target object, matching station criteria, and applying arm torques toward the target point. The report discusses medium success rate and drift limitations.
Code-level details
The simulation calculates mass/inertia terms, simplified Coriolis terms, reaction torques, Euler integration, base motion, and joint angular velocities.
Actions map to base thrust commands of 0, +10, or -10 and arm/base torque commands of 0, +0.01, or -0.01 per decision step.
The agent observes relative velocity, end-effector distance, target point, base-frame distance, vehicle and target state, forces, and torques.
Arm torques are applied only once the vehicle is within station tolerance and sufficiently close to the target object's velocity.
Human demonstrations used keyboard control and a metronome-timed torque pattern to create more consistent soft-touch training data.
The report found PPO with BC/GAIL and no extrinsic reward was the most successful tested paradigm, with about 35-50% success.
Simulation telemetry
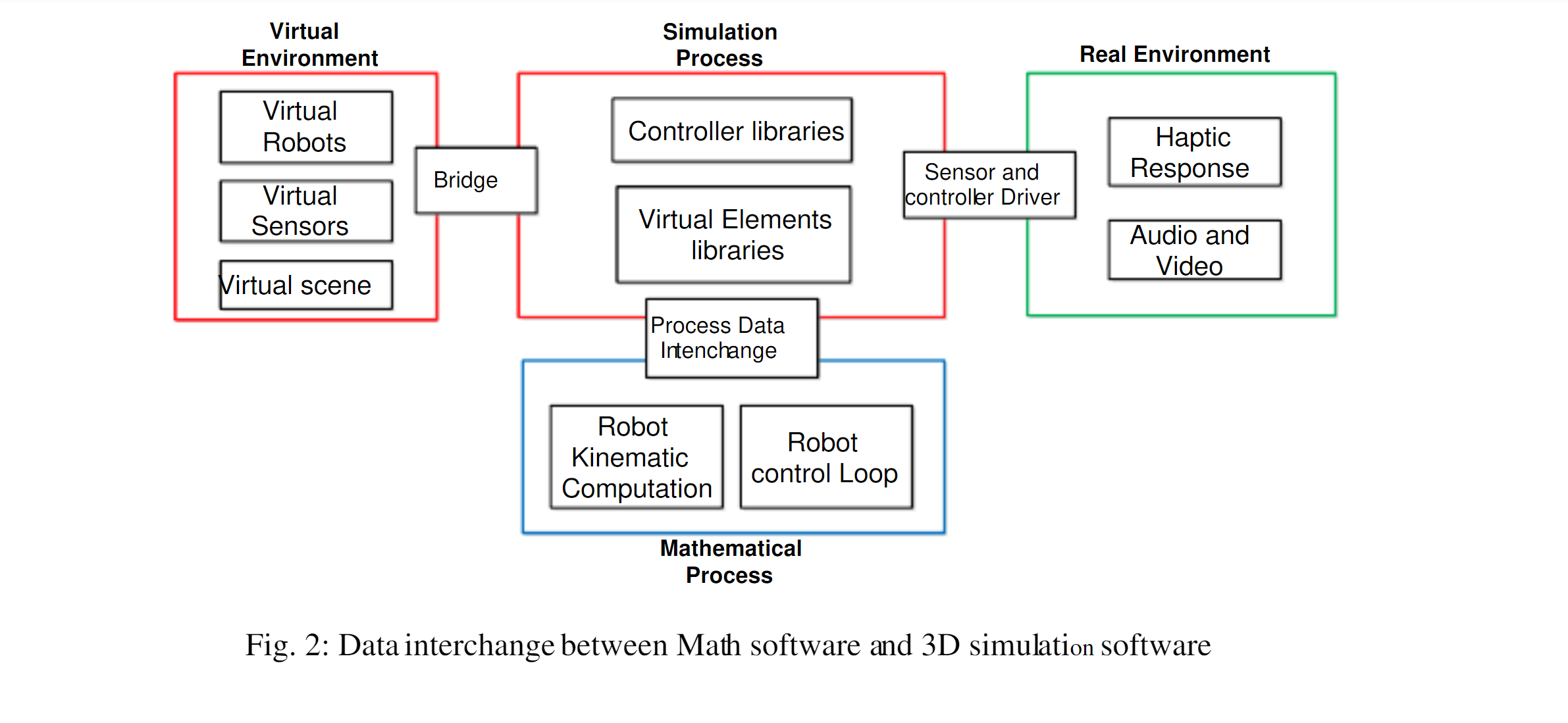
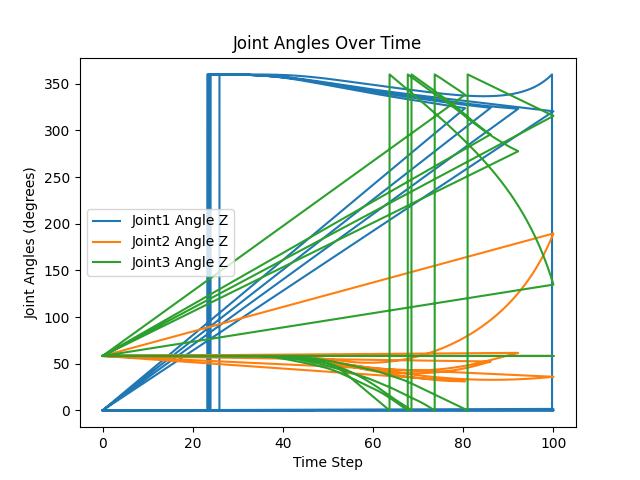
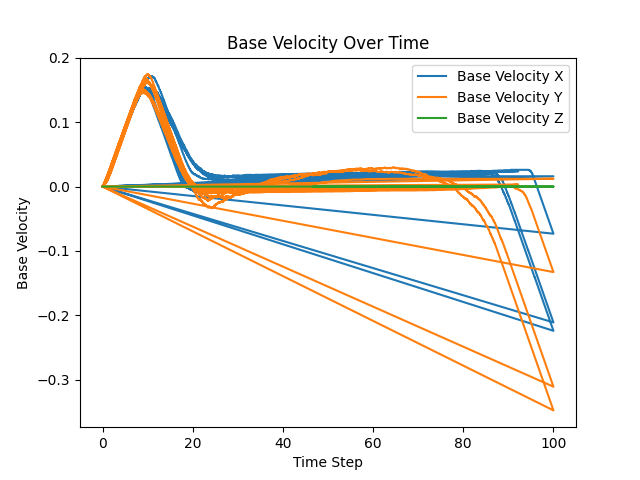
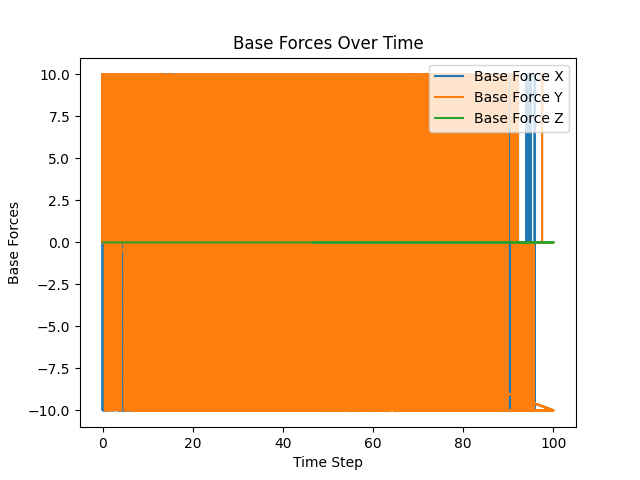
Future iteration